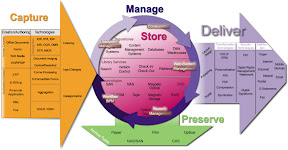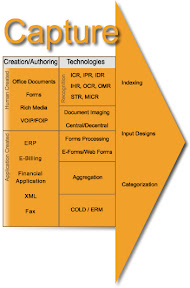
The Capture Model comprises how business content, whether paper or electronic, is transported into a content repository for reuse, distribution, and storage. The Capture Module contains functionalities and components for generating, capturing, preparing and processing analog and electronic information. There are several levels and technologies, from simple information capture to complex information preparation using automatic classification. Capture components are often also called Input components. Manual capture can involve all forms of information, from paper documents to electronic office documents, e-mails, forms, multimedia objects, digitized speech and video, and microfilm. Automatic or semi-automatic capture can use EDI or eXtensible Markup Language (XML) documents, business and ERP applications or existing specialist application systems as sources. The first step in managing content is getting it into the IT infrastructure. While internal company documents are born, and remain, digital throughout their lifecycle organizations still needs to ingest a tremendous amount of paper-based communications from outside. Checks, invoices, application forms, customer letters, etc., all need to be turned into digital form for insertion into the content management electronic workflow and/or directly into storage. Capturing documents puts them in motion and enables the information contained in those documents to be acted upon. While organizations predominantly refer to capture as the digitizing of paper documents, capture can also mean ingesting electronic files into your content management environment.
Recognition Technologies; For an extended period of time organization have always (and will) need a tool that deciphers data from the abstract and perceived un-abstractable and this is where recognition technologies lend a hand below are a few of the ‘solidified’ and ‘fluid’ functions within the model. With the advancement a voice and television over IP future recognition engines will need to be designed and developed to extract information from these new forms of digital (content) media. For the purpose of the domain the definition is:
The sensing and encoding of printed or written data by a machine and is a process that occurs in thinking when some event, process, pattern, or object recurs. Thus in order for something to be recognized, it must be familiar. This recurrence allows the recognizer to more properly react, and has survival value.
Optical/Intelligent Character recognition (OCR/ICR); Optical/Intelligent Character Recognition (OCR/ICR) engines can achieve high recognition rates equal to human accuracy when documents are properly designed, printed, and controlled. Optical character recognition, usually abbreviated to OCR, is computer software designed to translate images of handwritten or typewritten text (usually captured by a scanner) into machine-editable text, or to translate pictures of characters into a standard encoding scheme representing them (e.g. ASCII or Unicode). OCR began as a field of research in pattern recognition, artificial intelligence and machine vision. Though academic research in the field continues, the focus on OCR has shifted to implementation of proven techniques. Optical character recognition (using optical techniques such as mirrors and lenses) and digital character recognition (using scanners and computer algorithms) were originally considered separate fields. Because very few applications survive that use true optical techniques, the optical character recognition term has now been broadened to cover digital character recognition as well. Early systems required "training" (essentially, the provision of known samples of each character) to read a specific font. Currently, though, "intelligent" systems that can recognize most fonts with a high degree of accuracy are now common. Some systems are even capable of reproducing formatted output that closely approximates the original scanned page including images, columns and other non-textual components.
Optical Mark Recognition (OMR); Optical Mark Recognition (OMR) is the process of capturing data by contrasting reflectivity at predetermined positions on a page. By shining a beam of light onto the document the capture device is able to detect a marked area because it is more reflective than an unmarked surface. Some OMR devices use forms which are preprinted onto paper and measure the amount of light which passes through the paper, thus a mark on either side of the paper will reduce the amount of light passing through the paper. It is generally distinguished from optical character recognition by the fact that a recognition engine is not required. That is, the marks are constructed in such a way that there is little chance of not reading the marks correctly. This requires the image to have high contrast and an easily-recognizable or irrelevant shape. Recent improvements in OMR have led to various kinds of two dimensional bar codes called matrix codes. For example, United Parcel Service (UPS) now prints a two dimensional bar code on every package. The code is stored in a grid of black-and-white hexagons surrounding a bullseye-shaped finder pattern. These images include error-checking data, allowing for extremely accurate scanning even when the pattern is damaged. Most of today's OMR applications work from mechanically generated images like bar codes. A smaller but still significant number of applications involve people filling in specialized forms. These forms are optimized for computer scanning, with careful registration in the printing, and careful design so that ambiguity is reduced to the minimum possible.
Speech and Translation Recognition (STR); Speech and Translation recognition is the process of converting a speech signal either analog or digital to a sequence of words relative to the receiving audience, by means of an algorithm implemented as a computer program. Speech and translation recognition applications that have emerged over the last years include voice dialing, call routing, simple data entry, and preparation of structured documents. Voice Verification or speaker recognition is a related process that attempts to identify the person speaking, as opposed to what is being said.
Intelligent Handwriting Recognition (IHR); Intelligent handwriting recognition is the ability of a computer to receive intelligible handwritten input. The image of the written text may be sensed "off line" from a piece of paper by optical scanning. Alternatively, the movements of the pen tip may be sensed "on line", for example by a pen-based computer screen surface. Handwriting recognition principally entails optical character recognition. However, a complete handwriting recognition system also handles formatting, performs correct segmentation into characters and finds the most plausible letters and words. Hand-printed digits can be modeled as splines that are governed by about 8 control points. For each known digit, the control points have preferred 'home' locations, and deformations of the digit are generated by moving the control points away from their home locations. Images of digits can be produced by placing Gaussian ink generators uniformly along the spline. Real images can be recognized by finding the digit model most likely to have generated the data. For each digit model we use an elastic matching algorithm to minimize an energy function that includes both the deformation energy of the digit model and the log probability that the model would generate the inked pixels in the image. The model with the lowest total energy wins. If a uniform noise process is included in the model of image generation, some of the inked pixels can be rejected as noise as a digit model is fitting a poorly segmented image. The digit models learn by modifying the home locations of the control points.
Intelligent Pattern Recognition (IPR); Pattern recognition is a field within the area of machine learning. Alternatively, it can be defined as: "The act of taking in raw data and taking an action based on the category of the data.” As such, it is a collection of methods for supervised learning. Pattern recognition aims to classify data (patterns) based on either a priori knowledge or on statistical information extracted from the patterns. The patterns to be classified are usually groups of measurements or observations, defining points in an appropriate multidimensional space. A complete pattern recognition system consists of a sensor that gathers the observations to be classified or described; a feature extraction mechanism that computes numeric or symbolic information from the observations; and a classification or description scheme that does the actual job of classifying or describing observations, relying on the extracted features. The classification or description scheme is usually based on the availability of a set of patterns that have already been classified or described. This set of patterns is termed the training set and the resulting learning strategy is characterized as supervised learning. Learning can also be unsupervised, in the sense that the system is not given an a priori labeling of patterns, instead it establishes the classes itself based on the statistical regularities of the patterns. The classification or description scheme usually uses one of the following approaches: statistical (or decision theoretic), syntactic (or structural). Statistical pattern recognition is based on statistical characterizations of patterns, assuming that the patterns are generated by a probabilistic system. Structural pattern recognition is based on the structural interrelationships of features. A wide range of algorithms can be applied for pattern recognition, from very simple Bayesian classifiers to much more powerful neural networks. Holographic associative memory is another type of pattern matching scheme where a target small patterns can be searched from a large set of learned patterns based on cognitive meta-weight. Typical applications are automatic speech recognition, classification of text into several categories (e.g. spam/non-spam email messages), the automatic recognition of handwritten postal codes on postal envelopes, or the automatic recognition of images of human faces.
Magnetic Ink Character Recognition (MICR); Magnetic Ink Character Recognition was developed to permit the effective processing of checks. Checks consist of a single line of numeric data, and the font used (E-13B or CMC7) is highly stylized and printed with special magnetically conducting ink. Check and remittance readers were equipped with a magnetic reader that analyzed the graph created from a stylized number font and was able to accurately interpret them.
Intelligent Document Recognition (IDR); Intelligent Document Recognition (IDR) technologies originally developed for invoice processing and the electronic mailroom. IDR uses techniques from each of the above areas and eliminates the limitations. It is no longer necessary to know what the form layout looks like. It is no longer necessary to insert separators. It is no longer necessary to presort. Specific rules can make the data understandable. IDR has the ability to figure out what the document category is and apply the appropriate business rules. IDR, which is also called intelligent data capture works a lot more like humans, relying on training and an internal knowledge of the layout and content of generic forms types, which is used to understand and extract required information and initiate workflows to act on the content. That widens the types of forms that can be captured and reduces costs, but IDR also changes capture capabilities substantially into a series of tools that have the ability to interpret and extract data from all sorts of unstructured information. This functionality allows an expanded reach and can provide the front-end understanding needed to feed business process management (BPM) and business intelligence (BI) frameworks by providing information previously not easily accessible or available. The information can be input as scanned paper or document formatted information, whether it is data-centric, such as Word or PDF normal, or image-based. Typically that includes and leverages multiple different methods including pattern recognition, OCR and other recognition and search engines to locate and extract required information before applying business rules to it. IDR provides the ability to make sense of and help manage the unstructured, untagged information that is coming into the corporation or organization.
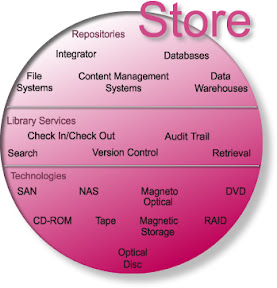
Document Imaging; Document Imaging is the process of capturing and pre-indexing documents and transmitting (relay-race) into a “System of Record” repository as a digitized image file regardless of original format, using micrographics and/or electronic imaging. Leveraging all type of recognition technologies in both a central and decentralized environment.
Indexing; in English parlance, indexing refers to the manual assignment of index attributes used in the database of a "manage" component for administration and access.
Web Forms/Forms Processing; Web Forms and Forms Processing is how forms are designed, managed, and processed completely in an electronic environment. A specialized imaging application designed for handling pre-printed forms. Forms processing systems often use high-end (or multiple) OCR engines and elaborate data validation routines to extract hand-written or poor quality print from forms that go into a database. This type of imaging application faces major challenges, since many of the documents scanned were never designed for imaging or OCR.
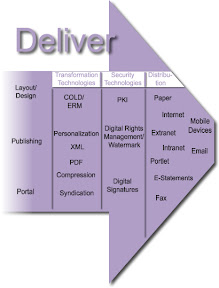
Computer Output to Laser Disk (COLD)/Enterprise Report Management (ERM); COLD/ ERM is the way documents and indexes from computer output (reports primarily). Once stored, the reports can be retrieved, viewed, printed, faxed, or distributed to the Internet. Often used for Internet Billing applications. Enterprise Report Management formerly known as computer output laser disk COLD technology, and, today, often written as COLD/ERM. This technology electronically stores, manages, and distributes documents that are generated in a digital format and whose output data are report-formatted/print-stream originated. Unfortunately, documents that are candidates for this technology too often are printed to paper or microform for distribution and storage purposes. This is mostly an aged terminology which over time will collectively assimilate into the “Document Management” functional model.
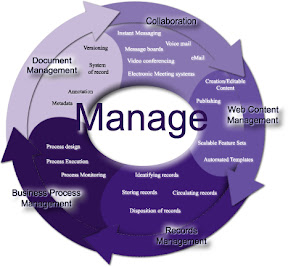
Aggregation; The ability to automate the collecting of units or parts into a mass or whole and address the creation of documents in concert with critical business processes from different creation, authoring tools and other systems producing a single work effort. Transform any document into a compelling, personalized communication that improves customer satisfaction and reduces operating costs. Assemble content from multiple sources into a single, complete, customized document package that presents a consistent company image — across multiple communication channels.
Categorization; categorization is the process in which objects (digital images) are recognized, differentiated and understood. Categorization implies that objects are grouped into categories, usually for some specific purpose. Ideally, a category illuminates a relationship between the subjects and objects of knowledge. Categorization is fundamental in prediction, inference, decision making and in all kinds of interaction with the environment. There are, however, different ways of approaching categorization. Categorization tasks in which category labels are provided to the learner for certain objects are referred to as supervised classification, supervised learning, or concept learning. Categorization tasks in which no labels are supplied are referred to as unsupervised classification, unsupervised learning, or data clustering. The task of supervised classification involves extracting information from the labeled examples that allows accurate prediction of class labels of future examples. This may involve the abstraction of a rule or concept relating observed object features to category labels, or it may not involve abstraction. The task of clustering involves recognizing inherent structure in a data set and grouping objects together by similarity into classes. It is thus a process of generating a classification structure. In conceptual clustering, this involves also generating a rule or description for each generated category.
Categorizing is the process of organizing documents, web pages, and all other unstructured content by putting each item into logical groupings, based on their contents category or classification.
Application Created Content; when looking at application created content they are two perspectives to review this from an obvious to you have pre-and post-creation. From a pre-content creation perspective having the ability to replicate the creation model provides a process ensuring the highest levels of compliance, however this has the creative residuals of the process and therefore the post-creation actions have the highest value to the business. Post-creation content is generally manageable if the proper thought is given to the residual and its final destination. Application created content needs to be managed from a historical perspective due to the predominant customer facing it provides, and the need to ensure the availability and proof of distribution. Application created content encompasses content, as types of environments, like Enterprise Resource Planning (ERP), eBilling (billing information sent by the customers or partners), financial applications and XML.
Human Created Content; Defining human created content is very broad the reason for that is they can be unstructured, unformatted and not validated against any backend systems or repositories. As an example of how human created content leverages office productivity products such as the product used to view this document, or to view a spreadsheet and even create presentation, but let's not forget the tool that is used most frequently and more successfully phone conversations and other rich media forms includes such content as streaming audio, video, PodCasting, and all OIP (Over Internet Protocol) content such as Voice, Fax and TV.
Voice/Fax Over Internet Protocol; Voice over Internet Protocol, also called VoIP, IP Telephony, Internet telephony, Broadband telephony, Broadband Phone and Voice over Broadband is the routing of voice conversations over the Internet or through any other IP-based network. Protocols which are used to carry voice signals over the IP network are commonly referred to as Voice over IP or VoIP protocols. They may be viewed as commercial realizations of the experimental Network Voice Protocol (1973) invented for the ARPANET.ce providers. Some cost savings are due to utilizing a single network to carry voice and data, especially where users have existing underutilized network capacity they can use for VoIP at no additional cost. VoIP to VoIP phone calls on any provider are typically free, while VoIP to PSTN calls generally costs the VoIP user. There are two types of PSTN to VoIP services: DID (Direct Inward Dialing) and access numbers. DID will connect the caller directly to the VoIP user while access numbers require the caller to input the extension number of the VoIP user. Access numbers are usually charged as a local call to the caller and free to the VoIP user[citation needed] while DID usually has a monthly fee. There are also DID that are free to the VoIP user but is chargeable to the caller. The ability to extract content from conversations and processed through a “Recognition Technologies” has the potential to aid value in may areas within a line-of-business.
Rich Media; was coined to describe a broad range of digital interactive media. Rich media can be downloadable or may be embedded in a webpage. If downloadable, it can be viewed or used offline with media players such as Real Networks' RealPlayer, Microsoft Media Player, or Apple's QuickTime, among others.
Office Documents; in computing, an office suite, sometimes called an office application suite or productivity suite is a software suite intended to be used by typical clerical and knowledge workers. The components are generally distributed together, have a consistent user interface and usually can interact with each other, sometimes in ways that the operating system would not normally allow. Most office application suites include at least a word processor and a spreadsheet element. In addition to these, the suite may contain a presentation program, database tool, and graphics suite and communications tools. An office suite may also include an email client and a personal information manager or groupware package.
Forms; Form refers to a document that is commonly used to request information and data. Forms are available in printed or electronic format, the latter being the most versatile as it enables the user to type the requested information using a computer keyboard and allows them to easily distribute the content contained within using the Internet and email.
Central/Decentralize; Central is the process of localizing image capture where objects are centralized for distribution most “heavy lifting” using “Recognition Technologies” are executed centrally. Decentralize is the process of dispersing decision-making closer to the point of service or action where simple functions exist.